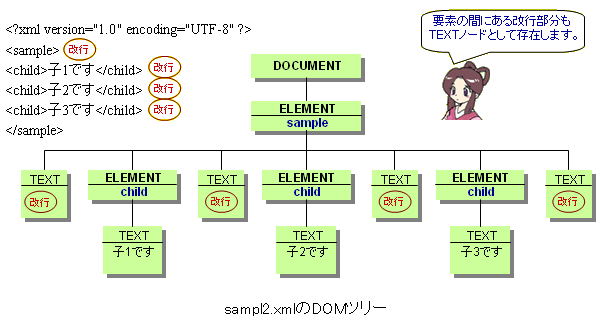
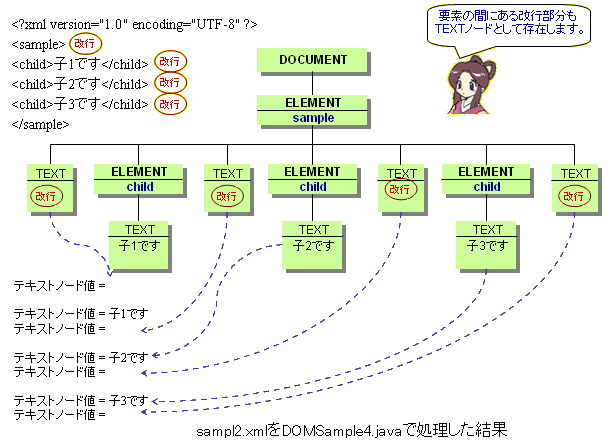
たけち: 前回は、兄弟ノードを取得するメソッドについて学んだね。
さらら: えぇ、そうして、XMLデータの内容をたどって見たわね。
たけち: で、今回は、テキストノードの値を取得するメソッドを学ぼう。
さらら: あっ、はい。
たけち: テキストノードの値を取得するには、getNodeValueメソッドを使うんだ。
さらら: getTextValueとかじゃ、ないのね。
たけち: あっ、気がついたね。実は、getNodeValueメソッドは、属性ノード、テキストノード、コメントノードなどのノードの値を取得するためのメソッドなんだ。
さらら: あっ、そうなんだ。
たけち: 今回は、テキストノードについて、その値を取得してみようね。まずは、getNodeValueメソッドの書き方を見ておこうね。
さらら: は〜い。