たけち: 前回は「データ型には単純型と複合型がある」ということを説明したよね。今日からその単純型についての説明をしようね。
さらら: 単純型といったら、xsd:string型とかxsd:int型とかxsd:positiveInteger型とかいったものが今まででてきたわね。それを知っていれば単純型は使えるんじゃないのかしら?
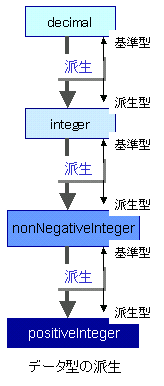
たけち: えーと(^^;) 確かにxsd:string型とかxsd:int型というのは、一番よく使う基本的な型なんだけれど、単純型はそれだけじゃないんだよ。xsd:positiveInteger型、つまり正の整数のデータ型があるということは、xsd:negativeInteger型、つまり負の整数のデータ型があってもいいよね。それから、実数のデータ型もあってもいいよね。
さらら: そう言われればそうね。
たけち: もう一つ考えておかないといけないのは、どれだけいろいろなデータ型が最初から用意されていても、あらゆる人のあらゆる要求には応えられないということだよね。例えばテストの点数を表す「テストの点数型」というのを考えると、たとえば0から100までの整数をとるのだけれど、こういうデータ型まで最初から用意していたらきりがないよね。
さらら: それはそうだわねぇ。