さらら: UTF-8ってなに?
たけち: XMLドキュメントの先頭にあるXML宣言のところにあったよね・・・
さらら: あっ、そういえば・・・いつもは encoding="Shift_JIS" を指定していたけど、UTF-8が基本だったわね。忘れてたわ。
たけち: そうだね。XMLドキュメントの文字コードの基本はUTF-8とUTF-16だったね。
さらら: そのUTF-8って、UTF-16もだけど、どんなものなの?
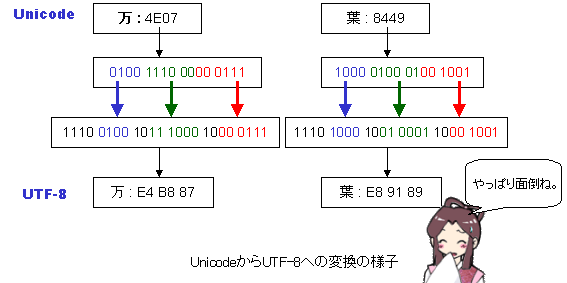
たけち: UTF-8のUTFというのは、Unicode Transformation Format(または 8-bit UCS Transformation Format)のことなんだ。Unicode(ユニコード)という文字コード体系に従った文字コードの交換形式のことなんだよ。
さらら: えっ、Unicode?