たけち: 前回は、DOMを処理してくれるパーサの利用方法とDOCUMENTノードの取得方法を学んだね。
さらら: それって要素ノードなんかを見てゆく出発点なのね。
たけち: 今回は、そのDOCUMENTノードの最初の子ノードから見ていこう。
さらら: はい。
たけち: あるノードの子ノードを見てゆくには、通常次のような方法をとるんだ。

|
2007年06月17日(日)更新 |
■子ノードを取得する
|
たけち: 前回は、DOMを処理してくれるパーサの利用方法とDOCUMENTノードの取得方法を学んだね。 さらら: それって要素ノードなんかを見てゆく出発点なのね。 たけち: 今回は、そのDOCUMENTノードの最初の子ノードから見ていこう。 さらら: はい。 たけち: あるノードの子ノードを見てゆくには、通常次のような方法をとるんだ。 |
|
|
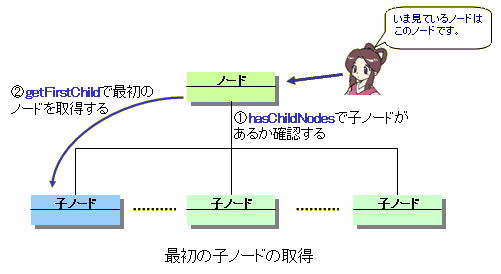
さらら: えっ〜と。。。最初に、自分のノードに子ノードがあるのを確認してから、一番最初の子ノードをとりに行くって事なのね。 たけち: そうだね。 |
■hasChildNodes、getFirstChild
|
たけち: じゃ、hasChildNodesとgetFirstChildの書き方を見ておこうね。 さらら: は〜い。 |
hasChildNodesメソッド
boolean | hasChildNodes() |
|---|---|
| 機能: このノードが子ノードを持っているかどうかを判断します。 | |
| パラメタ: ありません | |
| 戻り値: true このノードが子を持っている場合 false このノードが子を持っていない場合 |
getFirstChildメソッド
Node | getFirstChild() |
|---|---|
| 機能: このノードの子ノードを取得します。 | |
| パラメタ: ありません | |
| 戻り値: Node 子ノード null このノードが子を持っていない場合 |
|
さらら: あら、思ったほどは難しくなさそう。。。。ところで、ノードが子を持っていないことは、getFirstChildの戻り値がnullってことで分かるのね。 たけち: あっ、そうなんだよ。だから、hasChildNodesで確かめないで、いきなりgetFirstChildで子ノードを取得しにいくこともできるんだね。 さらら: で、戻り値がnullだったら、「あっ、無かったんだ」というわけね。 たけち: そうそう。 |
|
■サンプルXMLデータで試してみましょう
|
たけち: じゃ、前回使ったsample.xmlファイルを使ってgetFirstChildでDOCUMENTノードの子ノードを取得してみよう。 さらら: はい。次のXMLデータね。 |
| サンプルXMLデータ(1) sample.xml |
|---|
|
<?xml version="1.0" encoding="UTF-8" ?> |
|
たけち: 次にDOMサンプルプログラム(2)のソースコードを載せておくね。 さらら: はい。 |
| 行 | DOMサンプルプログラム(2) DOMSample2.java |
|---|---|
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
package dom.study.sample_1; |
|
さらら: あっ、22行目と23行目を見ればいいのね。 たけち: そうだね。まず、22行目で、子ノードがあるかどうかをみているね。 さらら: えぇ。 たけち: で、子ノードがある場合には、23行目で最初の子ノードを取得しているね。 さらら: わかるわ。 たけち: あとは、25行目と26行目で、取得した子ノードのノード名とノードタイプを見ているね。 さらら: はい。このプログラムを動かしてみたいわ。 |
|
■DOMSample2の実行例(sample.xmlの処理)
|
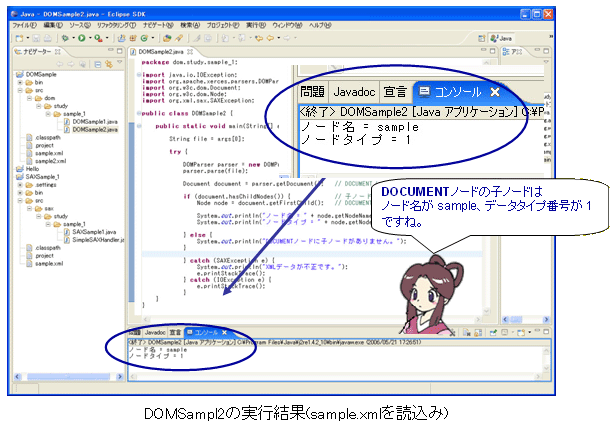
たけち: じゃ、sample.xmlファイルを指定して、DOMSample2プログラムを実行させてみよう。実行結果を図に載せておくね。 さらら: はい。 |
|
さらら: データタイプ番号が1、のノードタイプは要素ノード? たけち: そう、「要素ノード」だね。 さらら: 子ノードはsampleって名前の要素ノードなのね!! たけち: そうだね。 さらら: 子ノードを取ってきてるのが実感できてうれしい。 たけち: じゃ、今回はここまで。お疲れさま。 さらら: ありがと。 →次は、getNextSiblingで兄弟ノードをたどります。....... (^ ^; |
|