たけち: 前回は、子ノードを取得するメソッドについて学んだね。
さらら: えぇ、DOCUMENTノードの最初の子ノードを見たわね。
たけち: で、今回は、兄弟ノードを取得する方法を学ぼう。
さらら: あっ、はい。
たけち: あるノードの兄弟ノードをたどって見てゆくには、getNextSiblingメソッドを使うんだ。

|
2007年06月17日(日)更新 |
■兄弟ノードを取得する
|
たけち: 前回は、子ノードを取得するメソッドについて学んだね。 さらら: えぇ、DOCUMENTノードの最初の子ノードを見たわね。 たけち: で、今回は、兄弟ノードを取得する方法を学ぼう。 さらら: あっ、はい。 たけち: あるノードの兄弟ノードをたどって見てゆくには、getNextSiblingメソッドを使うんだ。 |
|
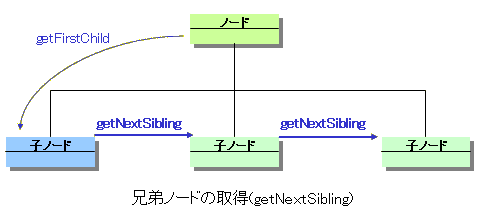
■getNextSibling
|
さらら: 横にたどっていく感じね。 たけち: そうだね。じゃ、getNextSiblingの書き方を見ておこうね。 さらら: は〜い。 |
getNextSiblingメソッド
Node | getNextSibling() |
|---|---|
| 機能: このノードの兄弟ノードを取得します。 | |
| パラメタ: ありません | |
| 戻り値: Node 次の兄弟ノード null このノードが次の兄弟を持っていない場合 |
|
さらら: 分かるわ。getNextSiblingの戻り値がnullになるまで兄弟ノードをたどることができるのね。 たけち: そうそう。 |
■サンプルXMLデータ
|
たけち: じゃ、今回は次のようなsample2.xmlファイルを使ってノードをたどってみよう。 さらら: はい。次のXMLデータね。 |
| サンプルXMLデータ(2) sample2.xml |
|---|
|
<?xml version="1.0" encoding="UTF-8" ?> |
|
さらら: childって名前の兄弟の要素が3つあるのね。 たけち: そうだね。プログラムを作ってたどる前にsample2.xmlのDOMツリーの概観を確認しておこう。 さらら: あっ、はい。 |
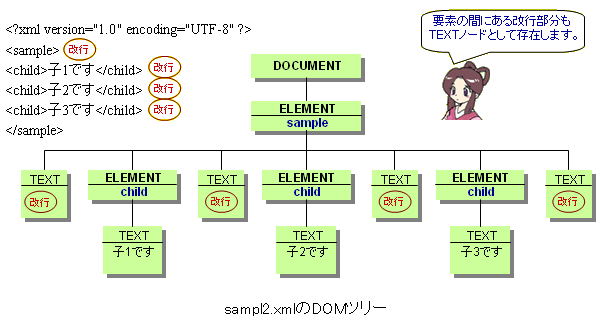
|
たけち: 人が見て分かりやすいようにsample2.xmlに入れた改行も、DOMツリーではTEXTノードとして扱われるからね。 さらら: わかったわ。でも、ちょっと面倒な感じね。 たけち: それについては、そのうち説明するからね。今回はあまり気にしないで。 さらら: はい。 |
|
■DOMサンプルプログラム(3)
|
たけち: じゃ、次にDOMサンプルプログラム(3)のソースコードを載せておくね。 さらら: はい。 |
| 行 | DOMサンプルプログラム(3) DOMSample3.java |
|---|---|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
package dom.study.sample_1;
import java.io.IOException;
import org.apache.xerces.parsers.DOMParser;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.xml.sax.SAXException;
public class DOMSample3 {
public static void main(String[] args) {
String file = args[0];
try {
DOMParser parser = new DOMParser(); // パーサの生成
parser.parse(file); // XMLファイルのパース
Document document = parser.getDocument(); // DOCUMENTノードの取得
traceNodes(document); // すべての子ノードをたどる
} catch (SAXException e) {
System.out.println("XMLデータが不正です。");
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
static private void traceNodes(Node node) {
Node child=node.getFirstChild(); // 子ノードを取得
while (child!=null) {
printNode(child); // ノードの情報を表示
traceNodes(child); // さらに子ノードをたどる
child = child.getNextSibling(); // 兄弟ノードを取得
}
}
static private void printNode(Node node) {
System.out.print("ノード名 = " + node.getNodeName() + " "); // ノード名
System.out.print("ノードタイプ = " + node.getNodeType() + " "); // ノードタイプ
System.out.println("ノード値 = " + node.getNodeValue()); // ノード値
}
} |
|
さらら: えっ〜と。。。41行目の たけち: そうだね。33行目〜43行目のtraceNodes()メソッドで、DOCUMENTノードの最初の子ノードから順にたどっているんだ。45行目〜51行目のprintNode()メソッドで、ひとつひとつのノードの情報を表示しているね。 さらら: えっ、えぇ。 たけち: プログラムの細かいことはいずれ説明するから、ここではこのプログラムでsample2.xmlのDOMノードをどうたどるかを図で示しておくね。 さらら: はい。 |
|
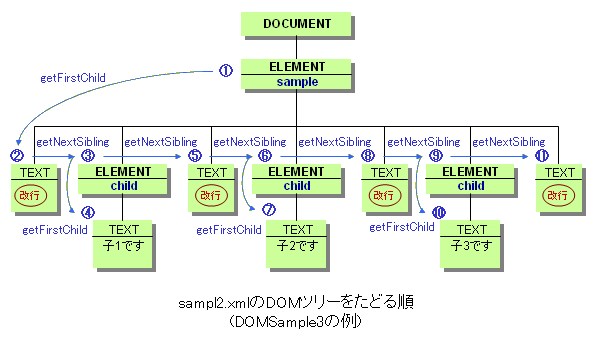
■DOMSample3の実行例(sample2.xmlの処理)
|
たけち: じゃ、sample2.xmlファイルを指定して、DOMSample3プログラムを実行させてみよう。実行結果は次のようになるよ。 |
| DOMサンプルプログラム(3) DOMSample3.javaの実行結果 |
|---|
|
ノード名 = sample ノードタイプ = 1 ノード値 = null ノード名 = #text ノードタイプ = 3 ノード値 = ノード名 = child ノードタイプ = 1 ノード値 = null ノード名 = #text ノードタイプ = 3 ノード値 = 子1です ノード名 = #text ノードタイプ = 3 ノード値 = ノード名 = child ノードタイプ = 1 ノード値 = null ノード名 = #text ノードタイプ = 3 ノード値 = 子2です ノード名 = #text ノードタイプ = 3 ノード値 = ノード名 = child ノードタイプ = 1 ノード値 = null ノード名 = #text ノードタイプ = 3 ノード値 = 子3です ノード名 = #text ノードタイプ = 3 ノード値 = |
|
さらら: 図でみせてもらった順にノードの情報が表示されているわ。 たけち: だいたいの雰囲気はわかったかな。 さらら: 子ノードを下にたどりながら、兄弟ノードをみていけばいいことは分かったわ。 たけち: 今回はそれでいいかな。お疲れさま。 さらら: えぇ、ありがと。 → 次は、getNodeValueでノードの値を取得します。....... (^ ^; |
|