たけち: そうだね。最初に説明したけど、実際にはInternet Explorer(IE 6.0)に組み込まれているMSXMLというのが変換してくれているんだね。
さらら: あっ、そっ、そう。そうだったわ。
たけち: このようにXSLTスタイルシートにしたがってXMLデータを変換してくれるプログラムをXSLTプロセッサって言うんだ。
さらら: あっ、そうなの。

|
2003年7月13日(日)更新 |
■XSLTプロセッサ
|
たけち: 前回は細かいことは気にせず、まずは簡単なXSLTスタイルシートを書いて、XMLデータをHTMLに変換してみたね。 さらら: えぇ。文字列がただつながっただけだったけど、ともかく変換はできたのよね。意味はまだよくわかんないけど。。。(^ ^; たけち: そうだね。今回から少しこのXSLTスタイルシートによる変換の様子をもう少し詳しく学んでみよう。 さらら: はい。 ※(注) 「理屈はともかく、まずは書き方を!!」という方は、xsl:templateへどうぞ。 |
|
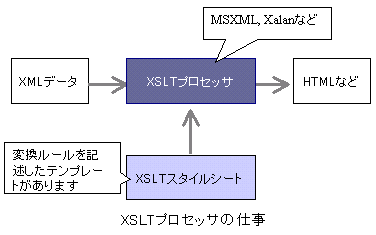
たけち: まずは復習だけど、XMLデータをHTMLなどに変換するには、変換前のXMLデータと、変換用のXSLTスタイルシートを使うんだったよね。 さらら: そうだったわ。 たけち: で、その変換は何がしてくれるんだっけ? さらら: えっ? えぇ~っと・・・あっ、Internet Explorer (^ ^; |
|
たけち: そうだね。最初に説明したけど、実際にはInternet Explorer(IE 6.0)に組み込まれているMSXMLというのが変換してくれているんだね。 さらら: あっ、そっ、そう。そうだったわ。 たけち: このようにXSLTスタイルシートにしたがってXMLデータを変換してくれるプログラムをXSLTプロセッサって言うんだ。 さらら: あっ、そうなの。 |
|
|
さらら: あっ、そういうことなのね。 たけち: うん。ちなみに、変換前のXMLデータをソースXMLデータって言ったりするから、覚えておいてね。 さらら: あっ、はい。 |
■ツリー構造モデル: ツリーチャート
|
たけち: で、これから少し、このXSLTプロセッサのおおまかな動きについて見てゆこうと思うんだ。少しずつ説明するからそんなに心配しないでね。 さらら: えぇ・・・(^ ^; たけち: 実際には、XMLデータについてはXPathというツリー構造モデルに基づいて考えるんだ。XPathの詳しいことはXPath(入門編)を参照してもらうことにして、ここではまずさららには、ツリー構造モデルについて知っておいて欲しいんだ。 |
|
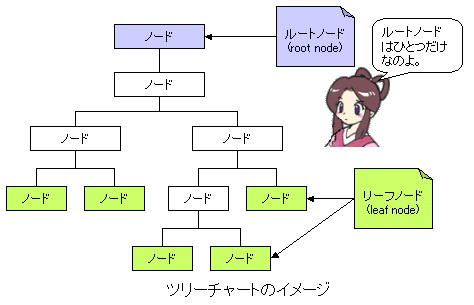
たけち: XMLデータの「構造」を扱うとき、ツリー構造というモデルが使われるんだ。そして、そのツリー構造の理解には図式的な表現が非常に分かりやすいんだけど、ツリー構造を図式的に表現したツリーチャート(木構造図)を使うんだ。 さらら: ツリーチャート?? それって、どんな図なの? たけち: ツリーチャートは木をひっくり返したような図なんだよ。 |
|
さらら: あっ、これってどこかで見たことがあるような・・・・ たけち: 簡単に説明しておくね。ツリー構造を構成しているひとつひとつのものをノードと言うんだ。ノードという言葉も、「木」のイメージからきていて、木の節(ふし)のことだね。 さらら: ふぅ~ん。木のイメージね。ひっくり返っているのがなんか変な感じだけど、わかるわ。 たけち: で、図で一番上の四角で示したノードのことをルート(根っこ)ノードというんだけど、これも木の根っこのイメージだね。 さらら: うんうん。 たけち: 図のルートノードの下に直線で結ばれたノードがあるね。さらに見てゆくと、それらのノードの下には、さらに直線で結ばれたノードがあるよね。で、ノードの下のノードが無い、つまり末端のノードをリーフ(葉っぱ)ノードと言うんだ。 さらら: なるほど、本当に木のイメージなのね。 |
|
たけち: こんな風に、ツリー構造ではノードが線で結ばれたものが上下関係をもっていて、データの構造を表すんだよね。 さらら: そうなんだ・・・でもこれとXMLデータとどういう風に結びつくのかしら?? たけち: じゃあ、次は、具体的なXMLデータをツリーチャートでもう少し詳しくみてみようね。 さらら: あっ、は~い。 |

|
|
→次回はXSLTによる変換の流れ(2)です。 (^ ^)v |